來源:北大青鳥總部 2023年08月21日 09:28
互聯網進入下半場,以數據資產為核心,數據分析做決策變為新一代互聯網特色。在數據分析領域,涌現的產品形態有數據中臺、數據倉庫、數據湖、數據集市,涌現的技術有實時計算、離線計算。涌現的工具框架有純計算類HIve/Spark/Presto、存儲框架Kudu、計算+存儲框架Clickhouse/Druid/Elasticsearch、Hadoop生態HDFS+YARN+MapReduce。隨著大家對數據分析的要求變高,希望耗時更短,使用更簡單,新的數據分析工具也出現了,那就是ApacheKylin.
ApacheKylin是一個開源的分布式數據分析引擎,基于Hadoop提供SQL查詢接口能力、多維數據分析能力,支持超大規模數據分析計算,能夠在亞秒級別內查詢超級大的Hive表數據,由eBay貢獻開源。劃重點:開源、亞秒查詢、SQL查詢、分布式,這表明Kylin免費、查詢速度快、上手簡單、高可用。我們互聯網人的新福音又來了,又快又好用還免費,真的是太好了。
在了解Kylin為什么快之前,我們先看看其它的工具為什么慢?我們以Hadoop家族的Hive來看,Hive它是基于Hadoop的數據倉庫工具,可將結構化的數據直接轉換成數據庫表,HIve系統將HQL語句轉化成MapReduce進行執行,本質上就是一款基于HDFS的MapReduce計算框架。所有的數據分析任務都轉化成MapReduce任務進行執行,當數據量變成PB、ZB級別時,當然就會變得很慢了,所有的數據也都存儲在HDFS中,獲取也很慢,業務人員在使用Hive時常常都需要等十幾分鐘或上半個小時。
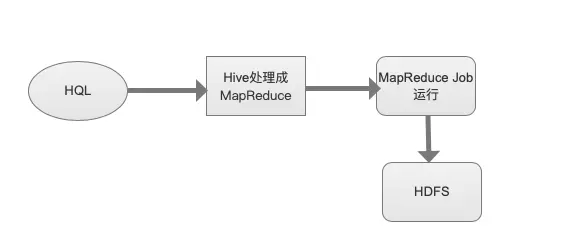
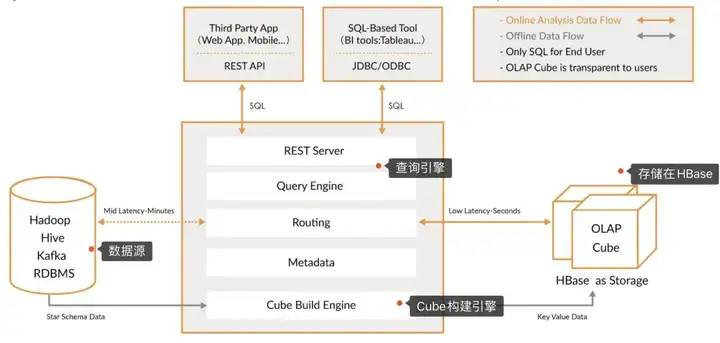
那ApacheKylin到底是什么樣子呢?在Kylin的技術架構中包含四大模塊,即數據源、中心處理引擎、存儲引擎、對外接口層,在數據源層可直接接收來自Kafka、RDBMS關系型數據庫如Mysql、數據倉庫Hive來的數據,在中心處理引擎層通過Cube構建引擎來做數據預聚合,聚合數據存儲Hbase,最后支持通過API接口方式直接調用(對于使用JAVA開發的服務,也可以通過JDBC直接鏈接Kylin),業務人員通過SQL語句直接查詢使用。
那Kylin又是怎么變快的呢?在Kylin的設計中,有一個模塊是Cube引擎,就是它幫助Kylin變快的。我們知道在數據分析的時候,經常要獲取多個維度的數據,就商品的售賣額來說,在做數據分析時,我們會關注某地區、某個時間點(比如雙十一)、某商品(比如最熱銷商品)等維度的售賣額。這些分析內容映射到數據倉庫時,分別是事實表和維度表,事實表按各個維度存儲數據,每個數據的結果就是度量。數據分析就是結合若干個維度查看度量值,找到其中變化的規律。
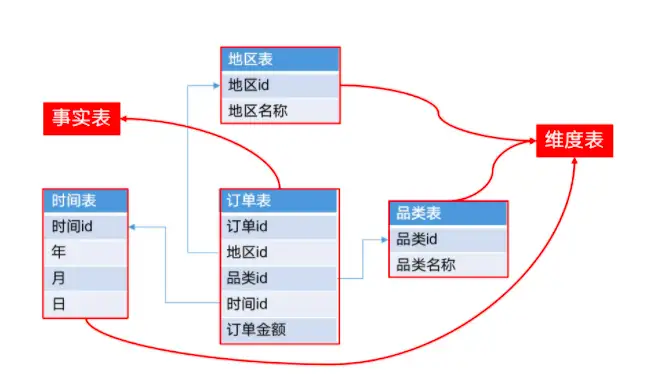
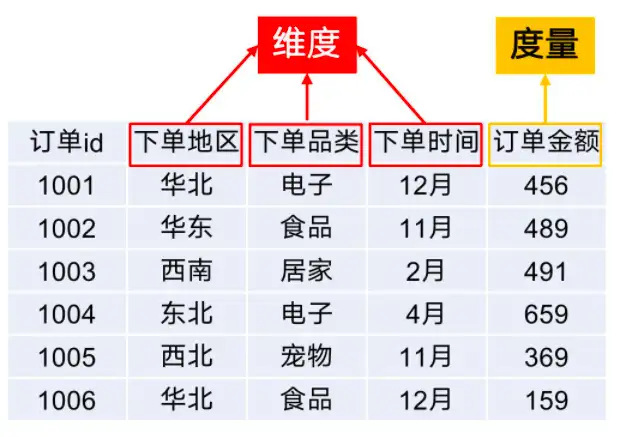
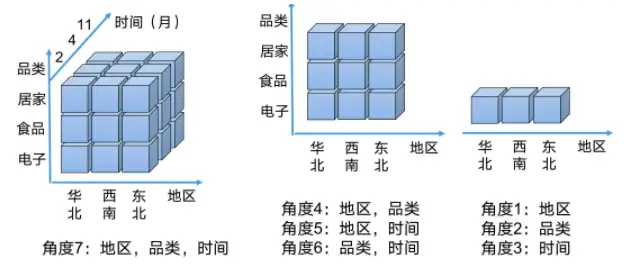
在Kylin中通過Cube立方體的概念從多維度把數據給串聯起來,接著我們剛剛的例子,因為有三個維度做分析,因此在Kylin中會建立一個三維的數據表(時間、地區、品類)。在數據分析時可以拆分到三維、二維、一維,三維包含地區&品類&時間,二維包含地區品類、地區時間、品類時間,一維包含地區、品類、時間,每一維度的數據都提前聚合號存儲在HBase中了,因此當數據分析時,直接拿聚合好的數據,當然比一個個的去執行MapReduce任務快了。
在計算層面快了,存儲層面Hbase也是毫不遜色的。Hbase的數據存儲實現方式是先將數據存儲在內存,當內存的數據量超過限定時在存儲磁盤,并且在磁盤中存儲的數據是有順序的(Hbase利用預寫日志和內存把隨機寫的數據先排序好之后再寫入內存)。因此在Hbase查詢數據時,會先從內存去獲取,內存找不到了再去磁盤獲取,在磁盤獲取的時候又是順序獲取(減少了磁盤尋道時間),所以當然很快了。在計算和存儲兩個方向都實現了加速,因此Kylin變快是毫無疑問的。
不過在使用Kylin時也需要注意一點,那就是Cube的多維度預聚合,如果聚合的維度比較多,比如有10個維度,那Kylin聚合出來的維度就會有2的10次方也就是1024多種,在Cube本身的聚合計算中也會變慢,因此業務可以根據自己需要來選擇聚合的維度。
目前Kylin在數據分析領域已經火起來了,很多互聯網公司,如滴滴、美團、攜程、京東等都把Kylin融入到了他們的數據分析模型當中,除此之外,在物聯網領域,它也正在大放異彩。工欲善其事,必先利其器,想要做好數據分析,有一款又快又好用的數據分析工具是必備的喔~



 手機端官網
手機端官網


 京公網安備 11010802020714號
京公網安備 11010802020714號