來源:北大青鳥總部 2023年08月02日 09:26
隨著互聯網、物聯網、5G、人工智能、云計算等技術的不斷發展,越來越多的數據在互聯網上產生,對互聯網的運營也開始進入精細化,因此大數據、數據分析、數字營銷開始變成每個互聯網企業的重點。在做數據分析時有OLAP、OLTP是我們必定會遇到的技術,在介紹OLAP引擎技術選型之前,我們先看看這兩個技術分別是什么意思?
OLTP(OnlineTransactionProcessing聯機事務處理),是傳統關系型數據庫的應用技術,提供日常的、基本的事務處理,比如在線交易之類。OLAP(OnlineAnalyticalProcessing聯機分析處理),是大數據分析的應用技術,提供復雜的分析操作、側重決策支持。目前主流的OLAP引擎包括Hive、Presto、Druid、Clickhouse、Kylin、Sparksql、Greeplum,每個引擎都有它各自的特點,我們今天就來簡單聊一聊,大家在實際使用時根據自己需求選擇就好~
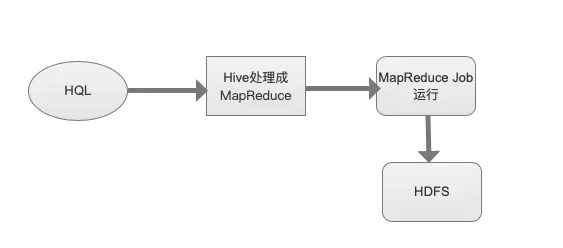
第一款OLAP引擎便是Hive。它是基于Hadoop的數據倉庫工具,可將結構化的數據直接轉換成數據庫表,HIve系統將HQL語句(類SQL語法)轉化成MapReduce進行執行,本質上就是一款基于HDFS的MapReduce計算框架,使用HQL就可以對存儲數據進行分析.Hive的優點是學習簡單(支持SQL語法)、擴展性強(底層基于HDFS),缺點就是太慢了(數據處理任務全轉換成MapReduce任務)。如果你的業務有數據分析的訴求,并且可接受一定的延遲,那么Hive是個不錯的選擇噢!
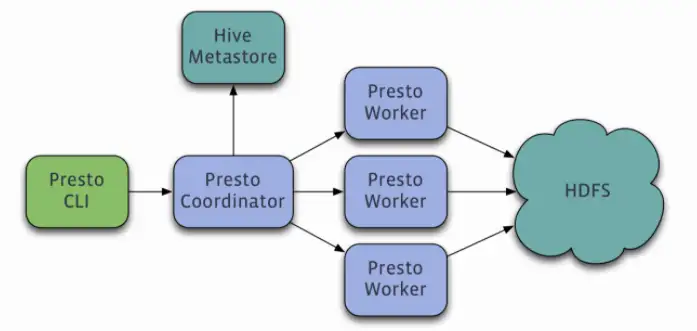
第二款OLAP引擎便是Presto。它是FaceBook開源的大數據分布式SQL查詢引擎,客戶端發出數據查詢請求時,先有語法解析器進行解析,解析之后再給到對應的節點執行任務。Presto通過自己系統內部的查詢和執行引擎來完成數據分析處理,所有的操作都在內存中完成,所以速度會快很多。Presto的優點是速度快、支持多數據源接入,缺點是容易內存溢出。
第三款引擎便是Clickhouse數據庫。它是俄羅斯開源的一款列式數據庫,在做數據分析時可直接選擇某幾列來作為分析屬性,獲取數據非常快,延遲低,如果按行讀取,每次只能讀取一個數據,有10000條就需要讀取1000次,降低了效率。此外在存儲層它實現了數據有序存儲、主鍵索引、稀疏索引、數據分區分片、主備復制等功能。所謂數據的有序存儲指的是數據在建表時可以將數據按照某些列進行排序,排序之后,相同類型的數據在磁盤上有序的存儲,在進行范圍查詢時所獲取的數據都存儲在一個或若干個連續的空間內,極大的減少了磁盤IO時間;此外在計算層ClickHouse提供了多核并行、分布式計算、近似計算、復雜數據類型支持等技術能力,最大化程度利用CPU資源,提升系統查詢速度。Clickhouse的優點就是快快快、分布式高可用,在數據分析這緯度看基本沒有缺點。
第四款引擎便是Kylin圖數據庫。它是Apache基金會開源的一款數據庫,也是結合當前人工智能知識圖譜的一個最佳數據庫。在Kylin中做數據分析的邏輯是用空間換時間,所有的數據都先預處理。在Kylin中通過Cube來做數據預聚合,比如我們想做雙十二某地區某品類的銷售額,因為有三個維度做分析,因此在Kylin中會建立一個三維的數據表(時間、地區、品類),在數據分析時可以拆分到三維、二維、一維,三維包含地區&品類&時間,二維包含地區品類、地區時間、品類時間,一維包含地區、品類、時間,每一維度的數據都提前聚合號存儲在HBase中了,因此當數據分析時,直接拿聚合好的數據處理展示。Kylin的優點就是簡單、快速,缺點就是可選數據分析維度太多。
本文介紹了四款大數據分析OLAP引擎,它們所表現出來的業態有數據倉庫、分析引擎、數據庫,但這絲毫不影響它們作為數據分析的引擎提供服務。互聯網的下半場已經進入了精細化時代,遠的不多,就看最近最火的社區團購生意,如果沒有背后的數據引擎做技術支撐,各互聯網巨頭們如何準確判斷用戶畫像、商品售賣趨勢、整體營收變化趨勢呢?不過每一款數據分析引擎都有自己適合的業務場景,企業根據自己使用成本、維護成本、業務場景進行選擇就好~



 手機端官網
手機端官網


 京公網安備 11010802020714號
京公網安備 11010802020714號