來源:北大青鳥總部 2023年06月28日 13:48
自大數據的概念被提出以來,企業對于數據信息變為數據資產的訴求越來越強烈,進而在技術領域出現了很多大數據計算引擎服務,最著名、使用最廣的莫過于MapReduce、Storm、Spark、Sparkstreaming、Flink了。它們都是在不同的時代背景下所產生的,又是為了解決每個階段所不能遇到的難題而新出現的解決方案,那么它們到底是什么呢?我們今天一一的來看看這些計算引擎寶貝們~
從處理的時間來看,我們可以把大數據計算引擎劃分為離線計算、實時計算兩類,離線計算一般是T+1的延遲,實時計算一般是秒級或毫秒級的延遲;從處理的數據量來看,我們可以把大數據引擎劃分為流式計算、批量計算兩類,流式計算是一次來一條處理一條,批量計算則是一次來多條處理多條。MapReduce、Spark屬于離線計算、批量計算引擎,Storm、Sparkstreaming、Flink屬于實時計算、流式與批量并存的計算引擎。
給計算引擎寶貝們分好類之后,我們一個個的來看看它們的絕技。MapReduce是大數據計算引擎的開山鼻祖,自Google著名的三篇論文發表之后,大數據處理開始流行起來,很多企業都使用Hadoop三件套MapReduce、HDFS、YARN來進行大數據的處理任務,所有的數據在進行處理前會劃分成大小相同的數據,經過Map模型初次處理數據,得到中間結果,再經過Reduce模型二次處理中間結果數據,最后得到分析數據,存儲在HDFS。在該模型中,存在兩個問題:
1、模型簡單,對于復雜的處理任務不好支持。對于復雜的統計分析任務,在MR模型中就需要經過多次轉換成中間結果,尤其是人工智能、深度學習類需要多次計算的場景就更不好使了;
2、不能有效的利用內存,在MR模型中所生成的中間數據都是存儲在磁盤中的,每次數據進入磁盤,再從磁盤讀取出來,非常的耗費IO,時間延遲太長了。因此Spark出現了。
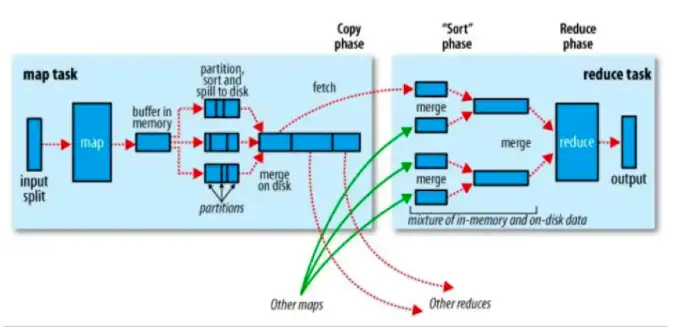
Spark是升級版的MapReduce計算引擎,在Spark中引入了RDD彈性分布式數據集(ResilientDistributedDatasets),在Spark中多個計算任務可以并在1個RDD里進行,假設我們的數據是存儲在HDFS當中,當要進行數據處理時,我們先把數據劃分成為多個大小相同的數據,一組任務是一個Stage,在Stage1階段進行Map計算,產生中間結果(RDD1),在Stage2階段進行Reduce計算,產生中間結果(RDD2),在Stage3階段再將之前階段的結果關聯起來(RDD3),最后給到Actions將RDD計算結果給到業務呈現。
在Spark模型中,它支持復雜的計算模型(支持多個Stage),也優化了磁盤性能問題(每個數據集任務都被抽象成RDD進行計算,存儲在內存中),以至于有人說Spark會取代MapReduce。在Spark模型流行了一段時間后,互聯網企業們對于數據的要求變得越來越高了,他們希望更快的得到數據分析結果,所以實時計算應運而生。

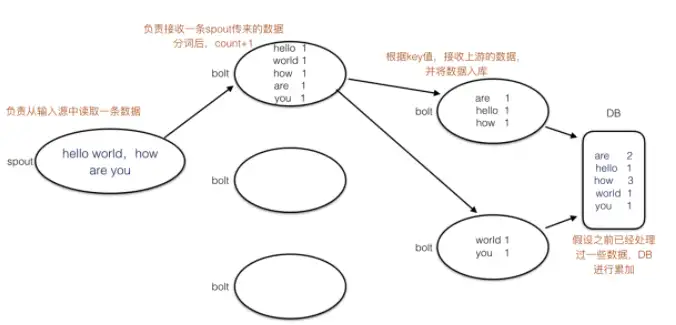
最先出現的實時計算框架是Storm,在Storm中有spout管口、bolt處理器、tuple元組的概念,spout負責從數據源接收數據tuple,按照一定的規則下放給到bolt進行處理,處理結束之后由數據庫存儲相應的結果。Storm處理模型中存在高可用和數據準確性問題,所謂高可用指的是spout節點掛掉了,數據計算任務怎么辦?
在MapReduce中數據掛掉了之后會重啟Map模型,而在Storm中也有一個對應的ACK機制,bolt接收到數據之后返回確認,處理完數據后返回確認,數據庫存儲數據后返回確認,基本要三輪確認后整個處理任務才算完成了;所謂準確性指的是數據重復處理問題,比如在數據處理過程中,處理節點bolt1處理完數據之后,發送給了接收節點bolt1,但接收節點bolt1還沒來得及確認,處理節點bolt1掛掉了,處理節點bolt2繼續重復處理bolt1的數據,從而導致在整個任務中數據是有冗余的。在Sparkstreaming中針對這兩個問題,提出了對應的解決方案。
Sparkstreaming是Spark的升級版本,在Sparkstreaming使用RDD模型將每次處理的數據轉換成1個數據集進行處理,減少了每次ACK的開銷,提高了效率,并通過exactlyone精準消費一次模型來保障數據的重復處理問題。它聯同分布式消息隊列Kafka(生產者消費者使用事務ACID模型來保障了數據消費和更新的原子性)在消息發送處、消息接收處實現了exactlyone。在Sparkstreaming中存在的問題是每次處理的數據量都是小批量的,如果我們想實現更小顆粒度的數據處理,就沒有辦法了,但這時候Flink應運而生。
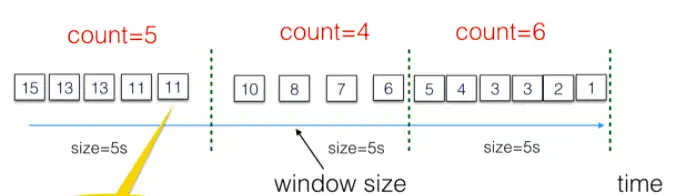
Flink通過分布式快照snapshot快照模型來實現數據按條處理,在整個數據處理任務當中,snapshot快照模型對每次操作都進行拍照,記錄當時處理現況,當處理發生故障時,Flink則停止當下處理,找到最近一次快照,把數據流恢復到當時的處理節點,讓業務按照當時處理情況繼續處理。并且為了更高效的處理任務,Flink還提供了Window窗口模型,支持用戶自定義每個窗口需要處理的數據或時長。
在本文介紹了MapReduce、Storm、Spark、Sparkstreaming、Flink五款大數據計算引擎如何處理大數據計算任務,各自的特點,所解決的問題,其實并不是說能解決最多問題的就是最好的,在采用大數據計算引擎之前,應當結合自己的業務特點、數據訴求,綜合開發成本、維護成本,再決定采用哪一款,最合適的才是最強的。



 手機端官網
手機端官網


 京公網安備 11010802020714號
京公網安備 11010802020714號