來源:北大青鳥總部 2023年05月18日 13:38
今天我們要給大家補的知識點便是分布式消息系統Kafka。
在互聯網海量數據、高并發、高可用、低延遲的要求下,使用消息系統來進行數據的轉發、系統之間的解藕是必不可少的,學習Kafka就先來看看Kafka的典型使用場景。
場景1之消息系統,即將生產者應用和消費者應用解藕,生產者的消息通過Kafka發送,消費者訂閱Kafka的消息。
場景2之日志收集,即通過Kafka收集各種服務的日志,再以統一接口服務的方式開放給各個consumer。
場景3之用戶活動跟蹤,即通過Kafka記錄web用戶或app用戶的活動,消費者訂閱該數據進行實時的分析。
場景4之運營指標,即通過Kafka記錄運營指標、監控數據,消費者再訂閱這些數據進行報警。
場景5之流式處理,即對接sparkstreaming、storm來實時處理數據。
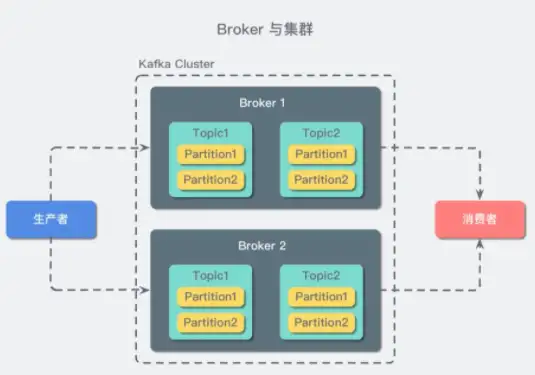
接著我們再繼續介紹Kafka的基本名詞概念,在Kafka中有Broker、Topic、Partition、Segment、Producer、Consumer五個基本概念。所謂Broker就是Kafka節點,一個服務器實例,存儲消息隊列數據;所謂Topic就是消息,比如購買商品后會有商品購買成功的推送,這就是一類信息;所謂partition就是分組,一個topic可以分為多個partition,比如購買商品后可按用戶地域進行消息的推送,北京地域是一個partition,上海地域是一個partition;所謂segment就是分段,將partition分為多段,存儲消息;所謂producer就是生產者,負責生產消息;所謂consumer就是消費者,負責消費消息。Kafka工作的流程就是producer發布消息,系統為每類數據創建一個topic,在broker集群持久化和備份具體的Kafka消息,consumer訂閱topic進行消費消息。
作為一個開源軟件,Kafka最重要的能力便是提供API。在Kafka中有四大API:即生產者API、消費者API、流API、連接器API。
通過生產者API,消息的生產者便可以直接與集群中的Kafka服務器連接,發送流數據到一個或多個Kafka的topic中。
通過消費者API,消息的消費者便可以直接與集群中的Kafka服務器連接,消費Kafka中topic的流消息。
通過流API,可順利的從topic中消費輸入流,生產輸出流,在流處理中,通過Kafkastreams api也將數據提供到大數據平臺、Cassandra、spark中進行數據分析。
通過連接器ConnectorAPI,開發者可以構建、運行可重復使用的生產者與消費者。
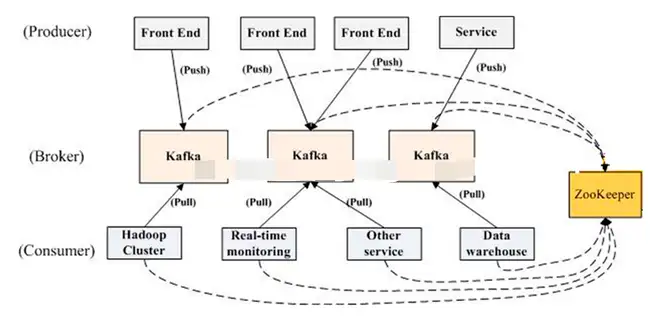
作為一個分布式消息系統,Kafka是如何實現分布式的呢?Kafka需要與zookeeper一起使用才能對外提供分布式消息系統能力。我們假設有這樣的一個場景,在Kafka集群中,有一個很大的topic要處理。我們先把這個topic放在代理服務器Broker1、broker2、broker3上,在broker1/2/3上分別包含分區partition1/2/3。當一個broker啟動時,首先會向zookeeper注冊自己的broker、topic、partition信息等meta元信息。當消費者啟動時,也會向zookeeper節點注冊自己的信息,監聽生產者的變化。那么數據是如何分布各個節點呢?事實上每個節點的數據都會在整個集群進行復制,比如在broker1中每個分區中的數據都會復制一份到該集群中的Broker2、broker3,由broker1作為主節點對生產者和消費者提供數據,當broker1節點掛掉時,通過使用zookeeper工具在剩下的broker2、broker3中選舉出新的主節點對外提供服務。因此在Kafka集群中所有的數據在每個broker節點都有,無論何時都保障了服務的高可用。
最后我們看看在Kafka中如何保障數據的可靠性呢?
第一是消息順序讀寫,如果生產者producer先寫入了消息1,再寫入消息2,那么消費者consumer則會先消費1再消費2;
第二是消息寫入到所有的Kafka節點后才會被認為該消息已提交;
第三是一旦消息已提交,只要有一個Kafka節點存活,數據就不會丟失;
第四就是消費者consumer只能讀取已提交的消息。通過這些機制,足以保障Kafka系統數據的可靠性了。
在本文,我們介紹了從使用場景、基本概念、重要能力、分布式保障、可靠性保障五個方面介紹了Kafka,如果在面試中面試官有問到Kafka或消息隊列相關的知識點,再也不怕被問住了~



 手機端官網
手機端官網


 京公網安備 11010802020714號
京公網安備 11010802020714號