來源:北大青鳥總部 2023年04月04日 15:42
傳統數據庫如Mysql、Oracle的出現解決了早期互聯網對于數據存儲、數據一致性的問題,但隨著互聯網、物聯網的快速發展而導致對數據存儲的要求不只是數據一致性,還有了更多特性需求。
傳統數據庫有幾個缺點:在大數據場景下讀取IO較高、無法存儲靈活的數據結構、表結構擴展不方便、全文搜索功能較弱(使用索引效率低)、不擅長出復雜關系型數據庫,因此非關系型數據庫NoSQL是極好的解決方案。
作為關系型數據庫的補充,再根據互聯網時代的需求不同,NoSQL可以分為:
支持高性能并發讀寫的Key-Value數據庫,如Redis;
支持海量數據訪問的文檔數據庫,如MongoDB、CouchDB;
支持大數據存儲和分析的列式數據庫,如HBase;
支持全文搜索的搜索引擎數據庫,如ElasticSearch。
Key-Value數據庫
所謂KV數據庫就是按照鍵值對進行存儲的數據庫,key是數據的標識,value是數據的值。Redis是典型的KV數據庫,可以存儲string、hash、list、set等數據結構。
我們以微博清除歷史粉絲為例,對于redis來說,只要使用RPOPkey從隊列的右邊出隊一個元素就可以了。是不是很簡單?
但如果是關系數據庫就比較復雜了,因為關系型數據庫是行式存儲,所以在建表時每條數據除了有數字編號之外,還有位置編號,用于判斷數據是否第一條,其次通過sql語句找到了第一條數據之后,再次執行sql刪除語句,最后更新從第二條開始的所有數據的位置編號。可以看到關系型數據庫需要進行多次SQL操作,實現非常麻煩,效率低,性能低。

Redis數據庫的主要缺點是不支持完整的ACID事務,但其實大部分業務也不需要嚴格遵守ACID原則,比如剛剛的微博粉絲案例,少一個或多一個粉絲對于我們并沒有什么影響。
文檔數據庫
所謂文檔數據庫就是可以存儲和讀取任意的數據,在使用之前不需要定義字段,讀取某個不存在的字段也不會報錯,目前大部分文檔數據庫存儲的數據格式是JSON,可以支持比較復雜的數據結構,MongoDB是典型的文檔數據庫。比如一個商品信息管理系統,商品的信息有商品ID、生產日期、品牌、貨號、口味、包裝方式、凈含量、產地、生產許可證編號、廠名、配料表、存儲方法、保質期、食品添加劑。其中口味是一個列表(因為口味可以有多個),產地是一個結構(包含省市區具體地址),保質期包含包裝方式、生產日期、存儲時長等。如果使用文檔數據庫,一個JSON就可以完全描述。
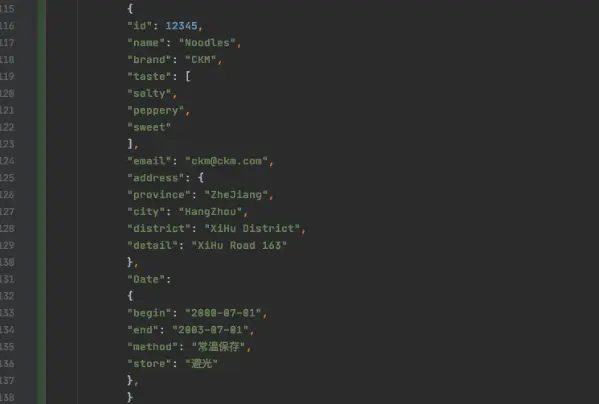
如果使用關系型數據庫,則需要設計多張表并且關聯起來,包含基本信息(有商品ID、價格、品牌三列)、地址(有省份、市區、鄉鎮、小區、門牌號四列)、配料表(有雞蛋、面粉、食鹽、添加劑等多列),表創建后再使用Join將所有的內容關聯起來,最終形成一個商品信息提供給到用戶。
文檔數據庫有兩個缺點。
缺點之一是不支持事務操作,比如使用MongoDB來存儲商品庫存,用戶付款、減庫存屬于一個事務操作,用關系型數據庫就很簡單,如果使用MongoDB來實現,就可能出現庫存減了但是用戶沒有付款的情況。
缺點之二是不支持join操作,比如我們想查詢購買了陳克明面條中的女性用戶,使用關系型數據庫,將用戶信息表和訂單表通過用戶ID來join操作就可以了,如果使用MongoDB,則需要查詢訂單表中買了陳克明面條的用戶,再查詢用戶中的女性用戶。
列式數據庫
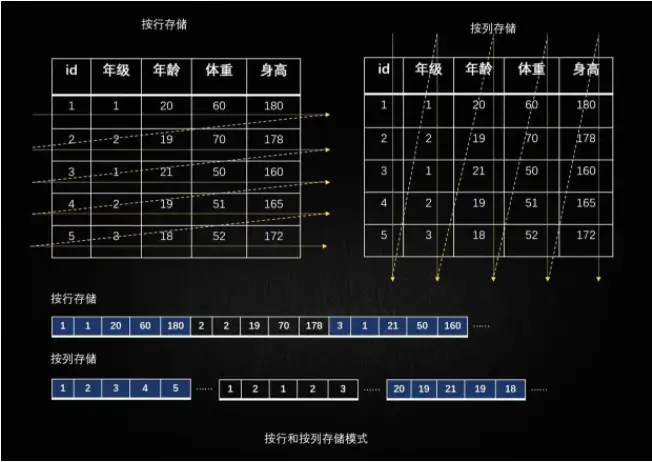
所謂列式數據庫就是按照列來存儲數據的數據庫,傳統的關系型數據庫是按行來存儲在磁盤,即行式數據庫,典型的列式數據庫是HBase。怎么理解行式和列式存儲呢?
以某個用戶信息登記表來說,按行存儲是二維表格中的每一行占據一塊連續的存儲空間,按列存儲則是每一列占據一塊連續的存儲空間。所以列式存儲數據庫非常適合大數據分析場景。
比如我們想分析某個區域的平均身高和體重,在mysql數據庫中需要獲取到每行的身高、體重數據,再來求平均,如果有10000個人,就需要請求磁盤空間10000次;在hbase數據庫中我們只需要請求兩次,獲取身高和體重這一列的數據求平均即可。
中期的時候是敏捷開發模型。因為互聯網上涌入的網民開始增多,大家的關注點開始變成好用、好玩,而此時一些有遠見的人開始注意到互聯網紅利,投身于互聯網,此時的開發模式演變成了敏捷開發模型。
敏捷開發模型面對的是頻繁的需求變化,要求快速開發。比較流行的實際案例則是Scrum、XP極限編程。在新迭代(一般2-6周)開始前,產品經理將需求拆分成具體的開發任務,研發人員進行任務認領,每日站會進行任務的review,直到開發完成,發布新的可用版本。
列式數據庫的缺點就是不適合小量數據、不適合隨機的更新數據、不適合有刪除和更新的實時操作、不適合ACID事務,因為列式存儲中要隨機的去更新數據或刪除某條數據,比較耗費磁盤IO,影響整體的性能。
搜索引擎數據庫
所謂搜索引擎數據庫就是支持在數據庫內通過關鍵字全文檢索,傳統的關系型數據庫是通過索引,比如like、where等語句來達到快速查詢,在全文檢索的情況下,需要整個表掃描,效率非常低。ElasticSearch是典型的全文搜索引擎數據庫,采用倒排索引的模式,建立從單詞到文檔的索引關系。比如現在我們有這樣的一個文檔集合,按單詞將文檔內容進行拆分,如文檔1-谷歌地圖之父跳槽Facebook,可拆分成單詞谷歌(單詞ID為1)、地圖(單詞ID為2)、之父(單詞ID為3)、跳槽(單詞ID為4)、Facebook(單詞ID為5),其余的依次拆分可得到如下的倒排索引表….

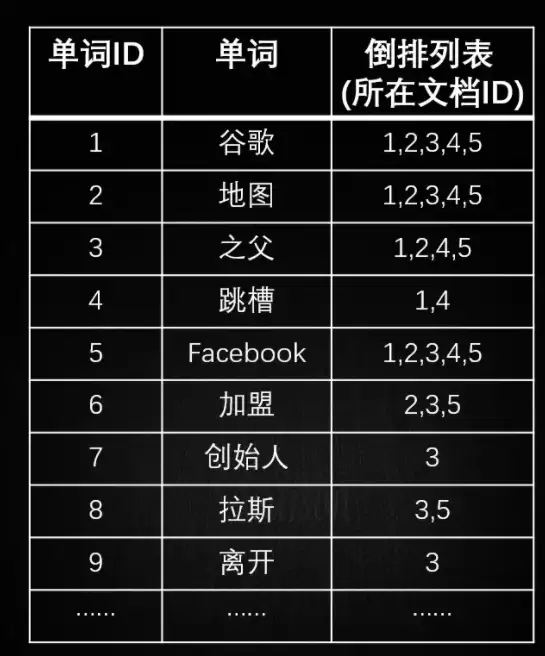
通過關鍵字就可以檢索文章了,我們在數據庫搜索谷歌時,所有的結果都會返回,搜索創始人時則只返回“谷歌地圖創始人拉斯離開谷歌加盟Facebook”。
SQL與NoSQL在是隨著互聯網的發展衍生的不同產物,在某一類業務的處理上都有自己的強項,在本文中我們介紹了四種類型的非關系型數據庫,你清楚了NoSQL哪些地方強了嘛?而在業務中,我們將SQL與NoSQL結合,取長補短,賦能業務即可~



 手機端官網
手機端官網


 京公網安備 11010802020714號
京公網安備 11010802020714號