來源:北大青鳥總部 2023年03月10日 13:50
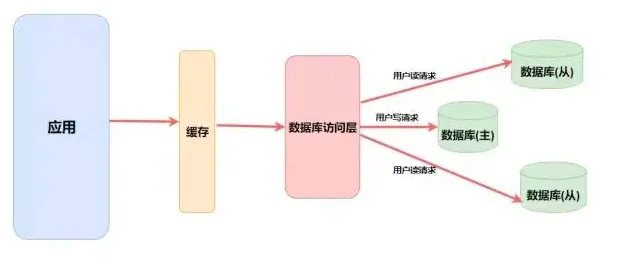
我們最常使用的應用,如淘寶、京東、抖音、微信等,全都是使用數據庫來進行數據的存儲。尤其是在接入互聯網網民越來越多的情況下,業務系統經常會面臨大量的數據請求,在一些大促場景,更會面臨突然間的請求量劇增,需要系統在極短的時間內完成上萬次的讀/寫操作,單個數據庫、傳統數據庫也難以承受該數據量,因此需要多類型的數據庫一起使用,充分利用數據庫的優點實現高并發,保障用戶體驗。
而眾多數據庫中,Redis便是程序員們最親睞、使用最多的數據庫,在各大企業招聘中也要求受聘者掌握redis的使用,疫情逐漸穩定,大量的招聘機會襲來,趕快來查漏補缺Redis(定義、特征、原理、數據結構、常用場景),看看還有哪塊兒不太熟悉,趕緊惡補,拿下心儀的offer吧~
Redis是一種內存數據庫,Nosql非關系型數據。
按照數據存儲的位置在磁盤還是內存,可以把數據庫分為磁盤數據庫(如Mysql、Oracle)、內存數據庫(如Redis)。對于磁盤數據庫來說,數據庫的事務操作機制成熟可靠,但是因為數據存儲在磁盤上,占用消耗的系統資源比較多、數據存取的速度比較慢、數據存取時間不一致且難以預測,所以當數據量比較大時就產生了新的解決方案,即把數據存儲在內存上,內存數據庫存取速度很快、數據一致、存取時間也易于預測,缺點就是內存比較貴,所以目前互聯網企業是內存數據庫與磁盤數據庫搭配在用。
按照存儲的數據關系模型把數據庫又拆分為關系型數據庫(如Mysql、Oracle)、非關系型數據庫(Redis、MongoDB)、大數據(HIve、Hbase、Clickhouse)。早期的時候,應用數據量不大,只使用數據庫就可以存儲所有數據并且保障良好的性能,但后來隨著業務的快速發展,應用數據量蹭蹭蹭的劇增導致于一個數據庫也不夠用了,運維們開始把數據庫進行主從復制,讀寫分離,分庫分表,并且在應用訪問和數據庫之間加了緩存層,把常調用的熱數據都放在緩存層,這緩存層就是Nosql非關系型數據庫。
Redis的典型特征便是單線程。在互聯網業務高并發的情況下,大部分應用程序、算法都是采用多線程思想,提高執行的并發度,然而redis卻是使用單線程模型進行設計,并且能承受住每秒幾百萬的請求量,那么為什么redis采用單線程設計呢?
Redis采用單線程模型來設計的原因主要有三個:
單線程模型維護性更好,便于開發和調試;
單線程模型也能很好的處理用戶請求;
Redis運行的操作性能瓶頸都不是CPU。
首先我們需要對齊一個概念,無論單線程還是多線程模型,設計的初衷都是保障系統的高性能。但是在采用了多線程模型后。就必須要同時引入并發控制來保證多個線程同時訪問程序的正確性,需要程序員額外去維護并發控制的代碼,加鎖,處理死鎖問題等,這樣提高了研發成本。
其次使用單線程模型也不等于系統不能并發的處理任務。在Redis中采用了I/O多路復用機制來并發處理客戶端的多個請求,并同時等待多個連接發送的請求。使用I/O多路復用技術可以減少系統的開銷,并且不需要額外創建和維護線程監聽客戶端的大量連接,減少了服務器的開發和維護成本。并且使用多線程也會帶來性能的下降,因為操作系統在執行任務時需要去保存加載線程的上下文從而帶來額外的開銷。
最后因為Redis是內存型數據庫,所以它的瓶頸一般不在CPU上,而多線程模型主要是在于并發的使用CPU資源,所以并不需要多線程去充分利用CPU資源。只需要管控好網路I/O來處理網絡傳輸帶來的延遲和等待客戶端的數據傳輸即可。
Redis有五種基本的數據結構,分別是strings字符串,hashes散列,lists列表,sets集合,sortedsets有序集合。
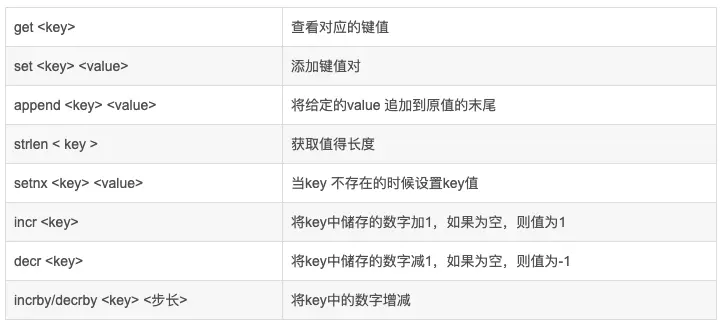
strings字符串類型支持setkey vaule設置值、getkey獲取某個key的值、msetkey1 value1 key2 value2批量設置值、mgetkey1 key2批量獲取值、incrkey自增指定的值、decrkey自減指定的值。
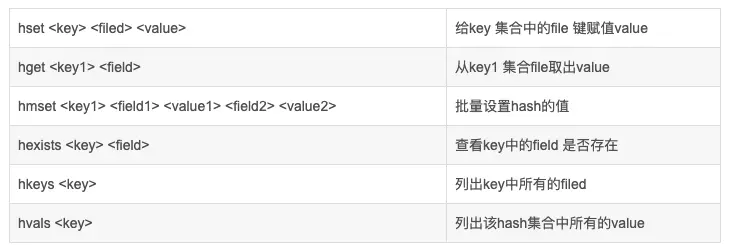
Hash支持hsetkey field value設置字典中某個key的值、hmsetkey field1 value1 field2 value2批量設置值、hget.
Keyfield獲取字典中某個key的值、hgetallkey獲取全部值、hmsetkey field1 field2 批量獲取值。
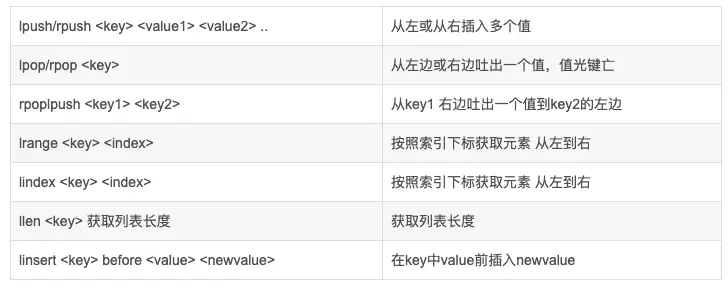
List即列表,支持lpushkey item1 item2 item3 從左往右入棧、rpushkey item1 item2 item3從右入棧、lpopkey從左出棧、rpopkey從右出棧、linsert key before|after item newitem在指定元素的前面或后面添加元素、lremkey count value刪除指定個數值為value的元素。
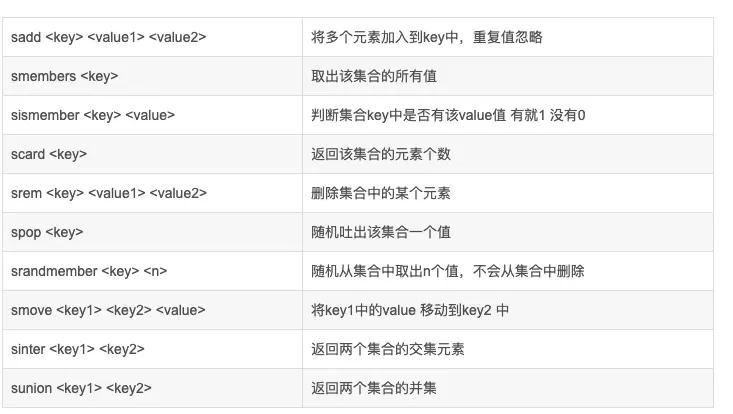
Set類型里面的元素不能重復,還可以對集合取交集和并集,通過Set可以實現取不同用戶之間的共同好友、溝通愛好等。saddkey value添加某個元素、sdelkey value刪除某個元素、sismemberkey value判斷是否是集合中的元素、srandmemberkey value隨機獲取指定個數的元素、stopkey count從集合中隨機彈出元素、scardkey獲取集合個數、sinterset1 set2獲取所有集合的交集、skiffset1 set2獲取所有集合的差集、sunionset1 set2獲取所有集合中的并集。
Zset是一個有序集合,通過它可以實現比如學生成績排行榜、視頻播放量排行榜等功能。

Redis基于內存存儲數據,并且底層由C語言開發,因此可以極大的提高查詢性能。Redis常用的場景包括緩存、時效性控制、計數器、社交列表、記錄用戶判定信息、熱門列表與排行榜、最新動態、消息隊列等。
緩存-對于熱點數據,用戶可能需要經常訪問,把數據放在Redis后,用戶就可以快速獲取數據。
時效性控制-我們注冊某個app或網站時,經常都是需要驗證碼,并且超過多少分鐘后就不能使用。
計數器-我們經常看的點贊數、瀏覽數、收藏數、分享數,利用redis遞增便可實現。
社交列表-我們經常看的用戶點贊列表、用戶分享列表、用戶收藏列表、用戶粉絲列表使用redis的hash類型數據結構便可實現。
記錄用戶判定信息-我們有時候需要知道用戶是否點贊、是否收藏、是否分享等,使用redis便可實現。
排行榜-根據某個value進行排序,可以獲取最新、最熱、點擊率最高的排名列表。
最新動態-按照時間順序排列獲取最新動態。
消息隊列-通過redis的list類型中的push、POP功能,可以實現消息中間件功能.
今天帶大家復(xue)習(xi)了redis,包含定義、典型特征及背后原因、常用的數據結構、使用場景等。在找實習、找工作的過程中,如果再有面試官問到你Redis,再也不用心慌慌啦!



 手機端官網
手機端官網


 京公網安備 11010802020714號
京公網安備 11010802020714號