來源:北大青鳥總部 2023年02月28日 16:29
“To be,or not to be:that is the question”(生存還是毀滅:這是一個問題),這是著名的莎士比亞悲劇《哈姆雷特》中的主人公一句非常經典的獨白,也是數百年來經常困擾人們的選擇問題。這段哈姆雷特式問題的臺詞,經常用來形容一個人在猶豫在思考時候的兩難情況,用現代人的說法就是“選擇困難癥”。人們經常糾結于各種選擇,生怕選錯了,就會陷入困境。

人們在面臨選擇難題的時候經常想:如果能未卜先知,那該多好。實際上,在人工智能領域,就有一種預測算法,利用樹杈的形狀,非常形象地來解決這種選擇問題,這就是決策樹算法,它是一個非常廣泛應用的算法,其原理是通過對一系列問題進行“是/否”的推導,最終實現決策。在機器學習發展到如今,決策樹算法越來越得到更多的應用,我們也可以說它是解決“選擇困難癥”的良藥。本文為了讓讀者朋友較好理解該算法,用python編程進行一個實際應用的示范。
決策樹算法是一種典型的、逼近離散函數值的分類方法。主要是先對數據進行處理,利用歸納算法生成可讀的規則和決策樹,然后使用決策對新數據進行分析。決策樹算法應用非常廣泛,例如在目前新冠疫情下,由于核酸檢測條件和資源有限,不能夠對所有人都進行檢測,因此對有疑似感染人員的一些行為特征進行推導,最終判斷其是否需要進行核酸檢測來進一步確診,也是很有必要的。比如調查和征詢病人的近期行為:“去過醫院或高危聚集地、防護措施是否到位、有病患接觸史、是否發燒咳嗽”,這四個行為特征來判斷是否需要對該人進行核酸檢測,從而進一步確診。
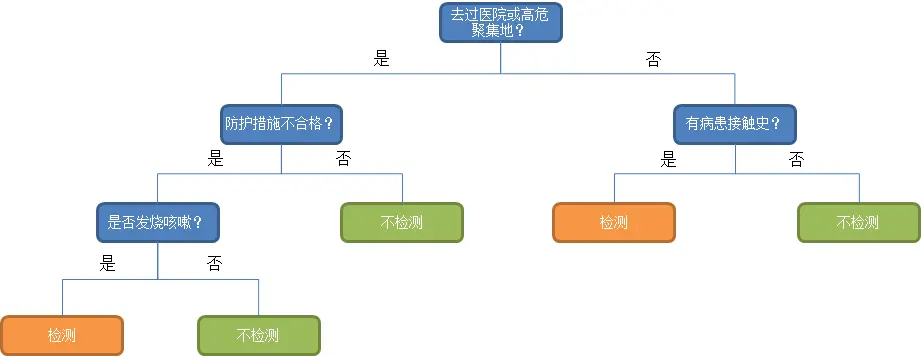
圖中最末端的5個節點,就是選擇后的判定結果,也稱為決策樹的樹葉。如果樣本的特征特別多、數據量大,就需要使用機器學習的辦法來建立決策樹的模型進行預測了。其中,決策樹算法的最大深度,也就是其max_depth參數,代表了決策樹的復雜程度,即上述例子中做出問題判斷的數量,問題判斷數量越多,就代表決策樹的深度越深,這個模型的計算也越復雜。
在上面的例子中,決策樹很形象地把新冠疑似人員的幾類行為做了推導,如果一個疑似人員雖然“沒有去過醫院或高危聚集地、但是有病患接觸史”,就要考慮做核酸檢測;如果一個疑似人員“去過醫院或高危聚集地、防護措施不到位、并且發燒咳嗽”,說明該病人感染可能性較大,就需要做核酸檢測。通過決策樹算法,對疑似人員進行選擇核酸檢測或不檢測的判定進行預測,解決了核算檢測的選擇問題。
(注:以上例子僅為了解釋決策樹算法的模擬描述,不一定代表真實情況)
隨著新冠疫情逐步得到緩解,長期宅在家中的人們都開始考慮去戶外游玩,可是天氣越來越熱、或者下雨、大風等,能不能帶家人一起出去游山玩水還得看老天爺的臉色。小明家有一個剛滿四歲的小孩,疫情期間,“小神獸”在家里都快憋瘋了,天天在家里是上躥下跳的。馬上就是周末了,小明看著家里被折騰的一片狼藉,他必須要做出周末是否能出行游玩的決策。同時他正好是一個大數據工程師,當然可以借助人工智能算法來預測天氣以及出行的可能性,從而做出一個全家出行游玩的計劃。本文就通過決策樹算法,利用積累了一定時間的歷史天氣數據,模擬一下小明的預測,看看這個周末他能不能帶全家一起出行游玩。
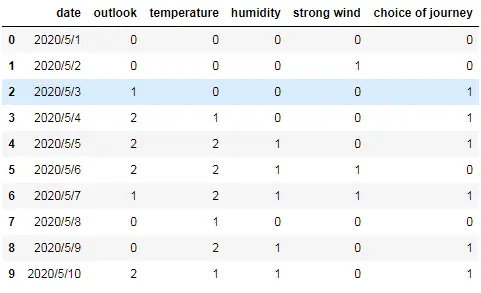
我們采用的數據集包含如下特征字段(為簡略過程,將數據集的各自段值全部轉換為數字):
日期-date、天氣-outlook(0-晴天、1-陰天、2-雨天)、氣溫-temperature(0-炎熱、1-適中、2-寒冷)、濕度-humidity(0-高、1-中、2-低)、大風-strong wind(0-有、1-無),另外還有一個輸出分類結果:出行的選擇-choice of journey(1-是、0-否)。
下面我們使用python導入數據集,并進行查看
#載入numpy、pandas,
import numpy as np
import pandas as pd
#使用pandas加載天氣數據集
data = pd.read_csv('weather.csv')
#顯示以下數據集前10行
data.head(10)
輸出運行結果如下:
將數據集不必要的字段裁剪掉。
#把去掉預測目標Choice of journey后的數據集作為訓練數據集X
data.drop(['date'], axis = 1, inplace = True)
X = data.drop(['choice of journey'], axis = 1)
#把預測目標賦值給y
y = data['choice of journey'].values
生成訓練集和測試集、使用決策樹算法建模并評估模型分數。
from sklearn.model_selection import train_test_split
#將數據集拆分為訓練數據集和測試數據集
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
#導入用于分類的決策樹模型
from sklearn import tree
#設定決策樹分類器最大深度為5
DT_clf = tree.DecisionTreeClassifier(max_depth=5)
#擬合訓練數據集
DT_clf.fit(X_train,y_train)
#打印模型的得分
print('決策樹模型得分:{:.2f}'.format(DT_clf.score(X_test, y_test)))
輸出結果為:
決策樹模型得分:0.85
可以看到,基于這個天氣數據集訓練的模型得到了0.85的評分,也就是說這個模型的預測準確率在85%,可以說預測準確率還不錯,應該能夠為小明解決出行的選擇問題了。
在這個過程中,決策樹在每一層當中都做了哪些事情呢?我們可以在Jupyter notebook中用一個名叫graphviz的庫(首先需要借助Anaconda安裝這個庫),它能將決策樹的工作流程展示出來。輸入代碼:
#導入graphviz工具
import graphviz
#導入決策樹中輸出graphviz的接口
from sklearn.tree import export_graphviz
#加載決策樹分類模型,將工作流程輸出到dot文件
export_graphviz(DT_clf, out_file=" weather.dot", class_names="choice of journey", feature_names=["outlook","temperature","humidity","strong wind"], impurity=False, filled=True)
#打開這個dot文件
with open("weather.dot") as f:
dot_graph = f.read()
#顯示dot文件中的圖形
graphviz.Source(dot_graph)
輸出結果為:
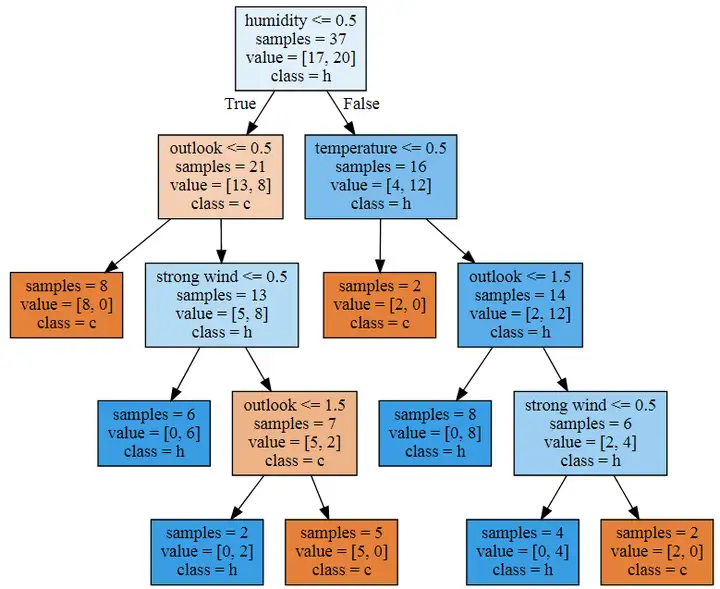
上圖非常清晰地展現了決策樹是如何進行預測的,可以看出,決策樹模型首先對濕度進行判斷,在濕度小于或等于0.5這個條件為True的情況下,決策樹判斷分類為c,如果是False,則判斷為h,到下一層則對天氣和溫度進行判斷,進一步對樣本進行分類,以此類推,直到將樣本全部放進2個分類當中。
模型建立好了,小明可以開始籌備周末的出行大計了,剛剛天氣預告廣播報道:本周末天氣為——多云、氣溫26度(適中)、濕度65%(稍高)、風力3級(無大風)。
按之前對特征字段設定的對應關系,各特征值解釋為數字是:[1,1,0,1]
我們可以利用上面步驟建立的決策樹模型來預測一下,看看小明周末能不能帶全家出去游玩。
#輸入本周末的天氣數據
weekend =[[1,1,0,1]]
#使用決策樹模型做出預測
pre = DT_clf.predict(weekend)
if pre == 1:
print("預測結果:[周末天氣不錯,可以去游玩!]")
else:
print("預測結果:[很遺憾,周末天氣不好,別去了]")
輸出結果如下:
預測結果:[周末天氣不錯,可以去游玩!]
小明得到以上預測結果也很興奮,馬上開始準備出行計劃、路線和設備。周末小明全家人高高興興地踏了一次青,大家反映都很不錯,小明的父親形象頓時偉岸起來J。決策樹算法解決了小明出行的“選擇困難癥”,小明也算利用他掌握的算法知識為家里做了一次貢獻。
決策樹算法(DecisionTree)在機器學習算法中,算是一個非常基礎的算法,使用和預測也比較簡單。以上的例子是一個理想狀況的闡述,在機器學習的實際項目中,決策樹算法經常會出現過擬合的問題,這會讓模型的泛化性能大打折扣。為了避免過擬合的問題出現,在決策書算法的基礎之上,科學家們又衍生出隨機森林(Random Forests)和梯度上升決策樹(Gradient Boosted Decision Trees,簡稱GBDT)算法,大大優化了決策樹算法。限于篇幅,本文對這兩個算法就不再深入介紹了,有興趣的讀者朋友可以自行學習和編程操作。



 手機端官網
手機端官網


 京公網安備 11010802020714號
京公網安備 11010802020714號