來源:北大青鳥總部 2023年02月07日 13:33
自從踏上了后端程序猿這條路,從此就和數據庫結下了不解之緣,每天都要CRUD
我們在使用Spring Boot的時候,有兩種常用的操作數據庫方案,一種是使用MyBatis框架,另一種就是Spring Data JPA,而且Spring Boot官方默認支持的也是Spring Data JPA,從名字上也能看出來,當然是因為它和Spring是一家人了。
為什么這么說呢?舉個例子:如果大家用過MyBatis的話應該會發現,MyBatis依賴的artifactId是mybatis-spring-boot-starter,而接下來我們要講的Spring Data JPA依賴的artifactId卻是spring-boot-starter-data-jpa,從這個名字關鍵字(mybatis、jpa)的順序上,就可以看出來誰才是親生的。

通常情況下Spring Boot官方支持的技術,在起名字的時候都是以spring-boot-starter-xxx來命名,而第三方主動適配Spring Boot的技術,通常名字都是xxx-spring-boot-starter的命名方式。
接下來我們就來一起看下這個親生的"兒子"為什么值得我們學習。
首先,來看下什么是Spring Data JPA,是Spring生態中,基于Spring Data框架實現JPA規范的一個持久層抽象,Spring Data JPA底層實現了Hibernate框架,所以在使用的過程中可以少寫很多SQL,因為大部分基礎的CRUD方法Spring Data JPA都已經幫我們實現了,幾乎可以在不寫具體實現代碼的情況下完成對數據庫的操作,除了基礎的CRUD操作外,Spring Data JPA還提供了諸如分頁、排序等常用功能,極大的提高了開發效率。
接下來,就開始進入實戰環節,通過一個小案例,來體驗Spring Data JPA的高效
常言道:"工欲善其事,必先利其器",這句話放在程序開發中也是非常適合的。
在開始之前呢我們要先準備數據,使用Navicat(可以自選)先創建一個數據庫,命名為kgc。數據庫創建好之后,創建一張用戶表,表名為t_user ,添加三列數據,列名分別是:
? id 唯一標記
? username 用戶名稱
? age 年齡
插入三條數據,數據庫腳本如下:
| # 數據庫腳本文件 SET NAMES utf8mb4; -- ---------------------------- -- Table structure for t_user -- ---------------------------- DROP TABLE IF EXISTS `t_user`; CREATE TABLE `t_user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `username` varchar(255) NOT NULL, `age` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=13 DEFAULT CHARSET=utf8; # 插入數據 INSERT INTO `t_user`(username, age) VALUES ('張三', '18'); INSERT INTO `t_user`(username, age) VALUES ( '李四', '20'); INSERT INTO `t_user` (username, age) VALUES ('王五', '22'); |
數據準備好之后,就可以開始集成Spring Data JPA了,使用SpirngBoot Initializr 創建SpringBoot基礎工程,因為我們是做持久層開發,所以此時需要添加一些數據庫相關的依賴
數據庫驅動依賴
這里如果不指定版本默認是8.0的版本,當然你也可以指定版本
| <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency> |
添加Spring Data JPA依賴
| <!-- Spring Data JPA依賴 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency> |
如果你不想手動添加依賴,也可以在創建項目的時候通過工具選擇,如下圖:
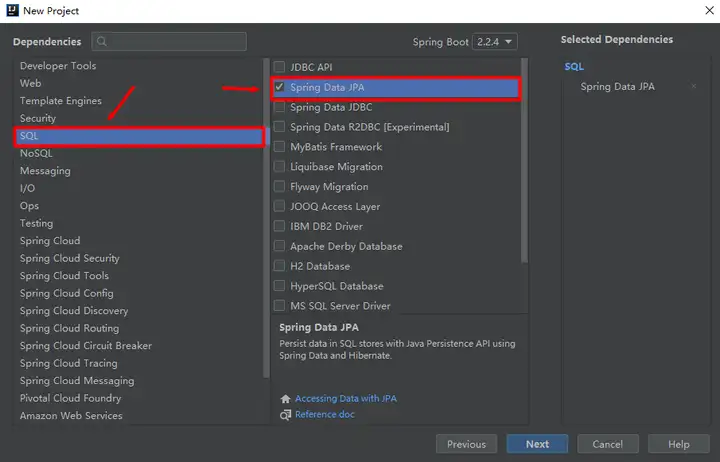
在application.properties屬性配置文件中配置兩部分內容:
數據源
jpa相關配置
| #配置數據源信息 spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver spring.datasource.url=jdbc:mysql://localhost:3306/kgc?useUnicode=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai spring.datasource.username=root spring.datasource.password=root # 加載hibernate自動更新數據庫結構 spring.jpa.hibernate.ddl-auto=update # 控制臺輸出sql語句 spring.jpa.show-sql=true |
創建User,并實現序列化接口Serializable,要注意實體類上的這些注解的使用
| @Table(name="t_user")//table指的是和哪個表映射 默認是user @Entity(name = "t_user") //實體類名和數據庫表名映射 public class User implements Serializable{ @Id @GeneratedValue(strategy= GenerationType.AUTO) private Integer id; // 用戶id @Column(name = "username") private String username; //用戶名 @Column(name = "age") private Integer age; // 年齡 // 省略 setter、getter方法 } |
@Entity:表示這是一個實體類,項目啟動時會自動針對該類生成一張表,默認的表名為類名,name屬性表示自定義生成的表名。
? @Id:表示這個字段是一個id
? @GeneratedValue:表示主鍵的自增長策略
? @Column:表示根據屬性名在表中生成相應的字段,如果字段名和屬性名不相同,可以使用name屬性指定
要注意的是用戶模塊的UserRepository接口,這里暫時不需要寫任何方法,因為JpaRepository已經幫我們實現了很多常用的方法,如果需要使用特殊的方法可以自定義。
| public interface UserRepository extends JpaRepository<User, Integer> { } |
默認實現的方法,如下:
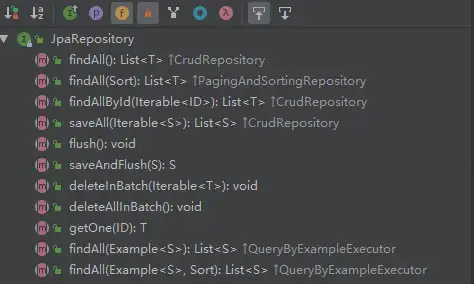
這些方方法,基本滿足了我們日常的CRUD操作,大家可以跟著這個案例,試一次其他的這些方法
接下來就可以編寫測試程序進行驗證,查詢所有的用戶信息
| @SpringBootTest @RunWith(SpringJUnit4ClassRunner.class) public class DemoApplicationTests { @Autowired private UserRepository userRepository; /** * 查詢所有用戶 */ @Test public void testSpringDataJpa() { // 調用findAll方法,查詢所有用戶 List<User> userList = userRepository.findAll(); for (User user : userList) { System.out.println(user); } }} |
可以看到控制臺輸入了如下數據,成功查詢出了所有的用戶數據,到此,大功告成,而我們一個SQL語句也沒有寫。Spring Data JPA幫我們節省了很多陪女朋友的時間,是不是很贊呢,從此以后再也不用擔心寫SQL了。




 手機端官網
手機端官網


 京公網安備 11010802020714號
京公網安備 11010802020714號